Whisper: Robust Speech Recognition via Large-Scale Weak Supervision
30 Oct 2024
Building a speech recognition system that is robust to various environments and doesn’t require any domain-specific fine-tuning.
Have you ever wondered how the subtitles are automatically generated when you watch YouTube videos? Automatic Speech Recognition (ASR) is a technology that converts human speech into written text. I’m pretty sure you have heard of (ICML 2023) Whisper at least once since it has been the most popular ASR system in recent days.
In this post, we’ll start with (1) briefly reviewing the literature in the ASR field when Whisper has been published. After that, I’ll explain (2) Whisper’s approach, followed by (3) experimental results and their interpretation. I’ll also share some (4) important academic/industrial works after Whisper. Note that this blog post includes my personal opinion!
ASR Literature before Whisper
| approach | generalization | scalability | low-resource robustness |
|---|---|---|---|
| supervised | ✓ | ||
| self-supervised | ✓ | ✓ | |
| weakly-supervised | ✓ | ✓ | ✓ |
Before Whisper, there were two main directions in ASR literature—supervised approach, and self-supervised approach. However, Whisper’s approach is weakly-supervised approach, having characteristics of both approaches to some extent.
Supervised Approach
- Learn direct sequence-to-sequence mapping between audio and text
- E.g. (SLT 2018) Toward Domain-Invariant Speech Recognition via Large Scale Training, (INTERSPEECH 2021) SpeechStew
- Pros
- Higher robustness and better generalization
- Cons
- Limited performance due to the limited size of supervised datasets
Self-Supervised Approach
- Learn self-supervised feature extractor → add additional modules on top of the feature extractor → fine-tune the module on the ASR dataset
- E.g. (NeurIPS 2020) wav2vec 2.0
- Pros
- No need for human labels for pretraining = Easy to scale up
- Infer text from good representation instead of raw audio = Effective for low-resource languages
- Cons
- Always require fine-tuning = bothersome, additional risk of failure
- Dataset-specific fine-tuning leads to bad generalization
Whisper’s Approach
Weakly-Supervised Approach
So, what is weak supervision? It means relaxing the requirement of annotation quality so that you can collect much more data, compared to the supervised approach. In other words, it is to sacrifice the quality of data to have a bigger dataset. This approach was already successful in the computer vision field, e.g. (ECCV 2020) BiT.
Whisper brings this approach to the ASR field, scaling the dataset to 680,000 hours. As weakly-supervised systems do in CV, Whisper also generalizes well to the existing benchmarks in a zero-shot setting.
Data Collection
The authors construct the dataset from the internet using an automated pipeline. They kept the data to be diverse in terms of audio quality, speakers, and languages for robustness. However, they found that diversity in transcript quality isn’t beneficial, thus applying various heuristics to filter bad-quality transcripts out.
Model and Training: Multitask Training Format
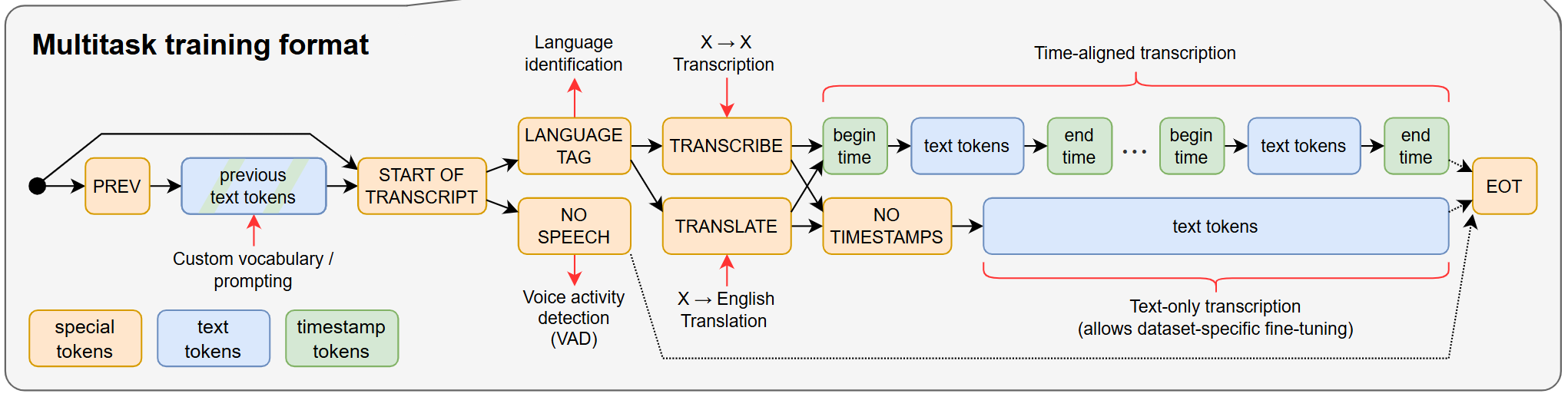
The authors used an encoder-decoder transformer to learn sequence-to-sequence mapping.
- Input: mel-spectrogram (an audio feature that is commonly used in speech/audio technology)
- Output: a sequence of tokens that is in multitask training format
- It is easy to understand multitask training format through examples:
- If a datapoint is (Korean audio, English text) without timestamp information, the target sequence has to be [
<|startoftranscript|>,<|korean|>,<|translate|>,<|notimestamps|>, …,<|endoftranscript|>] - If a datapoint is (French audio, French text) paired with timestamp information, the target sequence has to be [
<|startoftranscript|>,<|french|>,<|transcribe|>,<|3.51>, …, <4.88>, …,<|endoftranscript|>] - If a datapoint is background music that doesn’t pair with text, the target sequence has to be [
<|nospeech|>]
- If a datapoint is (Korean audio, English text) without timestamp information, the target sequence has to be [
- This format is well-designed to represent multiple tasks and various conditions, and therefore Whisper can use the same architecture for various tasks.
- It is easy to understand multitask training format through examples:
- Training Objective: cross-entropy loss over the tokens
Experiments
Since the experiments section in the original paper is too extensive, I’ll share only some of the experiments that are important (in my opinion). The main evaluation metric in the ASR field is the Word Error Rate (WER), but I guess it isn’t essential to understand the formula. You can simply think of the WER as a similarity measure, where the lower WER means the higher similarity between predicted text and golden text. The lower bound for WER is 0, where two transcripts are identical. However, there is no upper bound for WER. You can refer to (Wikipedia) Word error rate for more information.
In this section, you can find answers to the following questions:
- Is Whisper robust to various environments zero-shot? → English Speech Recognition Robustness
- How close the performance of Whisper is to the human performance? → Comparison with Human Performance
- Doesn’t multitask and multilingual training disturb the model of learning individual tasks? → Multitask and Multilingual Transfer
English Speech Recognition Robustness
Whisper’s goal is to work reliably without dataset-specific fine-tuning. In other words, it is to be robust on data distribution changes.
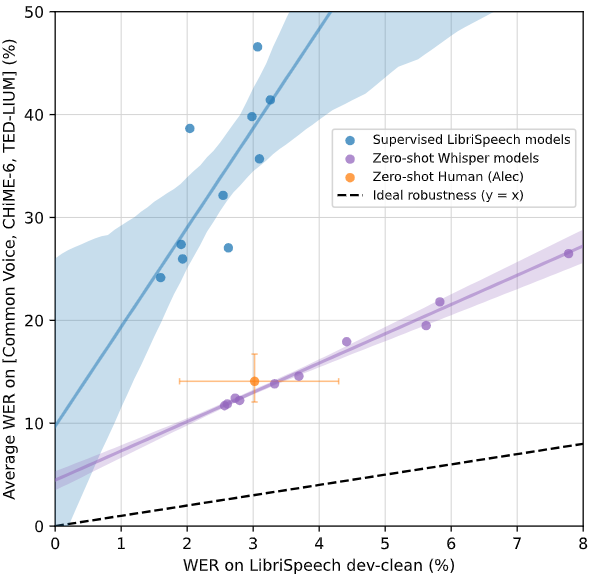
In the above figure, the x-axis corresponds to WER on one of the most popular English ASR datasets, and the y-axis corresponds to the average WER on three different datasets. By considering the ratio between the two WER, we can measure the models’ robustness against domain shift. The theoretical topline that always shows consistent performance regardless of the environment is represented as a dotted line with a slope of 1. They benchmarked various sizes of Whisper models and other models, showing Whisper models are much more robust against distribution changes than other supervised models. One additional finding is that the largest, and thus best-performing Whisper model (the leftmost point among the Whisper models) even beats the human performance.
Comparison with Human Performance
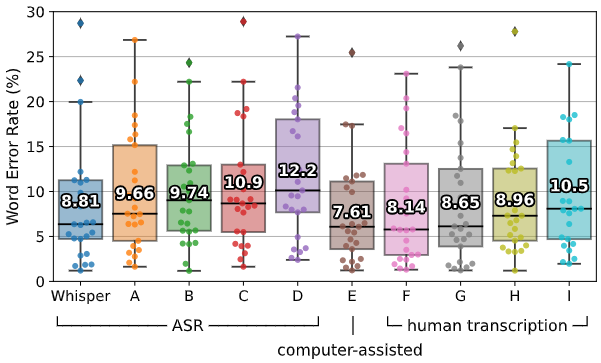
From the above figure, we know that computer-assisted human transcription (E) has the lowest WER which is 1.2%p better than Whisper’s. Whisper’s performance is not perfect, but it is very close to human performance.
Multitask and Multilingual Transfer
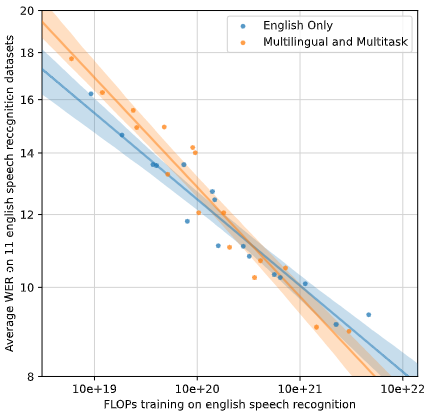
For me, this was the most interesting part of the paper. At the very first time, I thought the authors were way too ambitious. Whisper’s training data covers 97 languages and the authors even jointly train the model on many tasks—X→X transcription, X→en translation, voice activity detection, and time-alignment of the transcript. It is natural to worry about the potential interference between learning multiple tasks at the same time.
As the above figure says, for small models, there was a negative impact on English speech recognition performance from jointly training the model on several tasks. However, if the model is large enough, you can see there is no drawback in English ASR performance and even benefits from the multilingual and multitask training.
Another Way to Make Supervision Weaker?
I’d like to share a question that has been popped up in my mind at this point. Is relaxing the requirement of annotation quality the only way to make supervision weaker? Might this experiment mean, that if two tasks, A and B, are similar, then joint training on A and B could be another type of weak supervision for each other? If the model is large enough and capable of finding patterns that can be generally utilized for solving both tasks, this question shouldn’t sound silly.
ASR Literature after Whisper
- Dealing with Low-Resource Languages
- It is true that Whisper’s training data extensively covers various languages, but still, most languages have less than 1,000 hours of training data. If you have access to high-quality corpus on your target language, fine-tuning Whisper could be a great choice. Or, we can even more scale the data too!
- E.g. (GitHub) Whisper
large-v3, (INTERSPEECH 2023) Adaptation of Whisper Models to Child Speech Recognition
- More Accurate Timestamp Prediction
- Some people might need predicted timestamps, along with transcripts (i.e. when this utterance has been spoken?). However, Whisper’s approach to model timestamps isn’t that advanced, since there is no partial score when it predicts very close timestamp to golden timestamp. We can consider using soft labels for timestamp tokens or apply other post-alignment techniques.
- E.g. (INTERSPEECH 2023) WhisperX
- Efficiency
- Since the best-performing Whisper model is very large, people may want to make Whisper smaller and faster. This direction is very important since not all environments have enough computing capability.
- E.g. (arXiv 2023) Distil-Whisper, (GitHub) faster-whisper
- Real-Time Streaming
- The original Whisper without any adaptation to live video streaming platforms, can’t generate real-time video subtitles. There has been a lot of work using a technology called ‘transducers’ in this direction, but we might utilize Whisper in this direction too.
- E.g. (GitHub) whisper_real_time
- Adding Auxiliary Training Objectives
- Currently, Whisper is trained only with simple cross-entropy loss. Can we incorporate other training objectives from previous works such as unsupervised or self-supervised methods?
Commentary
- Some statistics about training data that might be important are missing, such as
<|translate|>/<|transcribe|>ratio,<|notimestamps|>ratio, etc. - Data collection source and the process is not transparent.
References
References are indicated inline. All the images are from the original paper.